Сөйлеуді тану жүйелерінің классификациясы
-
 aigerim_keulimzhai
aigerim_keulimzhai
- Жасанды интеллект / 26 қаңтар 2015, 01:04
- 4907
 Табиғи тілде сөйлеуді автоматты тану жасанды интеллект дамуының ең өзекті бағыты болып табылады. Бұл бағыттағы нәтижелер адам мен компьютер арасындағы тиімді қарым-қатынас орнату жабдықтарын жасау мәселесін шешуге мүмкіндік береді.
Табиғи тілде сөйлеуді автоматты тану жасанды интеллект дамуының ең өзекті бағыты болып табылады. Бұл бағыттағы нәтижелер адам мен компьютер арасындағы тиімді қарым-қатынас орнату жабдықтарын жасау мәселесін шешуге мүмкіндік береді. Сөйлеу технологияларының өндірістің кез-келген саласына енгізілуі зерттеу орталықтары мен өндіруші фирмалардың сөйлеуді танумен байланысты мәселелерге қызығушылығын арттырды. Сөйлеуді тануды зерттеумен бірнеше ғылыми облыстың мамандары елу жылдан бері айналысып келеді. Ол дауыспен басқарылатын кез-келген жүйелерде кеңінен қолданыс табуда. Дыбыстық енгізу табиғилық, жеделдік, енгізудің мағыналық дәлдігі, қоланушының қолы мен көзін босату, экстремалды жағдайда басқару мен өңдеу мүмкіндігі тәрізді артықшылықтарға ие.
Сөйлеуді автоматты тану – компьютердің акустикалық сөйлеу сигналын мәтін немесе сәйкес басқарушы командаға түрлендіру процесі. Бұдан күрделірек есеп сөйлеуді автоматты түсіну болып табылады, ол сөйлеуді тануға қоса танылған мәтіннің семантикалық талдауын қамтиды. Мұндай жүйелер әлі де зерттелу үстінде.
Кез-келген сөйлеуді тану жүйесіндегі сигналды өңдеу есебін келесі түрде көрсетуге болады:
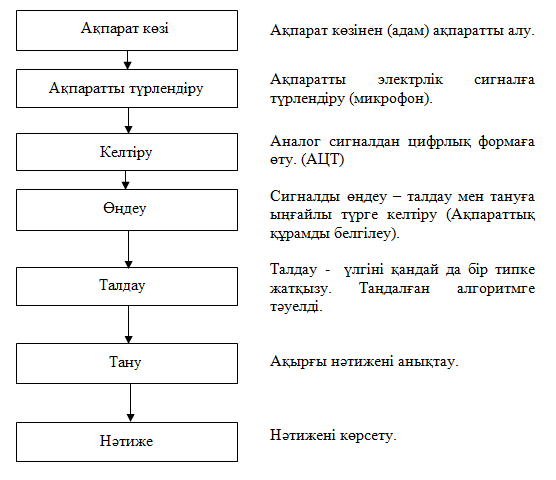
Сөйлеуді тану жүйелерін келесі белгілері бойынша классификациялауға болады:
— дикторға тәуелділігі;
— сөздік көлемі;
— танылатын сөйлеу ағынының сипаты.
Дикторға тәуелді жүйелер жекелеген қолданушыларға жасалады. Бұл жүйелер құрылымы бойынша қарапайымырақ, арзанырақ бірақ дикторлар тобына бейімдеуге немесе белгісіз диктормен жұмыс жасауға жарамсыз.
Дикторға тәуелсіз жүйелер кез-келген диктормен жұмыс істеу үшін жасалады. Бұл жүйелер әлі де қиындықпен дамып келеді, қымбатырақ болып табылады және дикторға тәуелді жүйелермен салыстырғанда тану сенімділігі төменірек болып келеді.
Дикторға бейімделуші жүйелер нақты бір дикторға немес дикторлар тобына баптау жасауға мүмкіндік береді. Мұндай жүйелер танудың жеткілікті тиімділігін қамтамасыз етеді, бірақ оны диктор немесе дикторлар тобына баптау уақыты ұзақ болуы мүмкін.
Сөйлеуді тану жүйесінің көлемі оның күрделілігімен тікелей байланысты және тану дәлдігі сипаттамасына елеулі әсер етеді. Сөздік көлемі қолданбалы жүйенің нақты талаптарына сәйкес анықталады. Кейбір қолданбалы программалар тек бірнеше сөзді талап етеді (мысалы сандар), ал келесілері өте үлкен сөздіктерді қажет етеді (мысалы, мәтінді автоматты теру жүйелері).
Әдетті сөздік көлемінің келесі градациялары қарастырылады:
— кішкентай сөздік – ондаған сөздер;
— орташа сөздік – жүздеген сөздер;
— үлкен сөздік – мыңдаған сөздер;
— өте үлкен сөздік – он мыңдаған сөздер.
Сөйлеу ағынының сипатына байланысты сөйлеуді тану жүйелері жеке сөздерді тану және үздіксіз сөйлеуді тану жүйелері болып бөлінеді. Жеке сөздерді тану жүйелері жеке сөздерді бөлек бөлек кідіріс жасап айту арқылы тануға арналған. Бұл әдіс танудың ең қарапайым түрі болып табылады, себебі мұнда сөздің бастапқы және соңғы нүктелерін табу оңай, және көршілес сөздер бір-біріне әсер етпейді. Бұл жоғары сапалы тануға қол жеткізуді қамтамасыз етеді.
Үздіксіз сөйлеуді тану жүйелері сөздер бірге, кідіріссіз табиғи түрде айтылатын сөйлеуді тануға арналған. Үздіксіз сөйлеуді өңдеу қиынырақ, оған себеп ең алдымен сөздердің бастапқы және соңғы нүктелерін белгілеудің қиындығы. Сонымен қатар «коартикуляция» мәселесі бар. Коартикуляция дегеніміз көршілес дыбыстардың өзара әсер етуі. Сәйкесінше, сөздің басы мен соңындағы дыбыстарға көршілес сөздердің басы мен соңындағы дыбыстар әсер етеді. Үздіксіз сөйлеуді тануға сөйлеу темпі де әсер етеді. Оның үстіне үздіксіз сөйлеуі тану жүйелерінің сөздік көлемі үлкен болуы шарт (он мыңдаған сөздер), себебі олар негізінен мәтінді автоматты теруге арналған.
Қазіргі жүйелерде сөйлеуді тануда екі түрлі тәсіл қолданылады:
— Дыбыстық белгілерді тану.
— Лексикалық элементтерді тану.
Алғашқы тәсіл сөйлеу фрагменттерін алдын ала жазылып алынған эталон бойынша тануға саяды. Бұл әдіс алдын ала жазылған сөйлеу командаларын орындау үшін арналған қарапайым жүйелерде кеңінен қолданылады.
Екінші тәсіл күрделірек. Оны жүзеге асыру кезінде жеке фонем, аллофон секілді лексикалық элементтер бөлініп алынады да буын және морфемдерге біріктіріледі.
Қазірде сөйлеуді тану жүйесін құру кезінде негізгі ұмтылыс келесі бағыттарда жасалады:
1. Үздіксіз сөйлеу — қолданушыларға табиғи (үздіксіз) сөз арасында кідіріс жасамай сөйлеуге мүмкіндік беру.
2. Дикторға тәуелсіздік — жүйенің сөйлеу сигналын қайталау арқылы компьютерді дербес баптаусыз сөздерді тану мүмкіндігі.
3. Үлкен көлемді сөздіктер — сөйлеуді тану жүйесінің қуаты мен тиімділігін арттыру мақсатында жалпы және арнайы пәндік облыстардан сөздердің үлкен санын тану мүмкіндігі.
-
+6